
Introduction
The car business has all the time been on the forefront of innovation, continuously in search of methods to enhance effectivity, security, and buyer satisfaction.
Predictive modeling provides a brand new dimension to this effort by enabling data-driven choices that profit producers, insurers, and shoppers.
On this mission, we give attention to predicting normalised losses for autos, an important metric for assessing vehicle threat and figuring out insurance coverage premiums.
Normalised losses are standardised metric that quantifies the relative threat of a automobile incurring insurance coverage losses.
This text leverages numerous machine studying fashions to supply correct and actionable predictions.
Vehicle insurance coverage dataset
Normalised losses are usually calculated based mostly on sure essential knowledge equivalent to historic claims knowledge, adjusted to account for various components equivalent to restore prices, automobile options, and accident frequency.
This enables for constant comparability throughout totally different automobile fashions.
The dataset includes 206 rows and 26 columns, providing complete insights into numerous autos. It consists of technical specs, insurance coverage threat scores, and normalised loss values, offering a strong basis for evaluation.
To entry the dataset please go to the next link, which incorporates an in-depth article detailing a previous exploratory evaluation performed on the auto dataset.
Goal of predictive modelling
On this mission, we intention to foretell normalised losses utilizing numerous machine studying fashions, together with Linear Regression, Ridge Regression, ElasticNet, Random Forest, Gradient Boosting, and Help Vector Machines (SVM).
The principle steps to realize this intention embrace:
- Knowledge Preprocessing
- Mannequin Choice
- Mannequin Analysis
- Hyperparameter tuning
- Function Significance
Knowledge Preprocessing
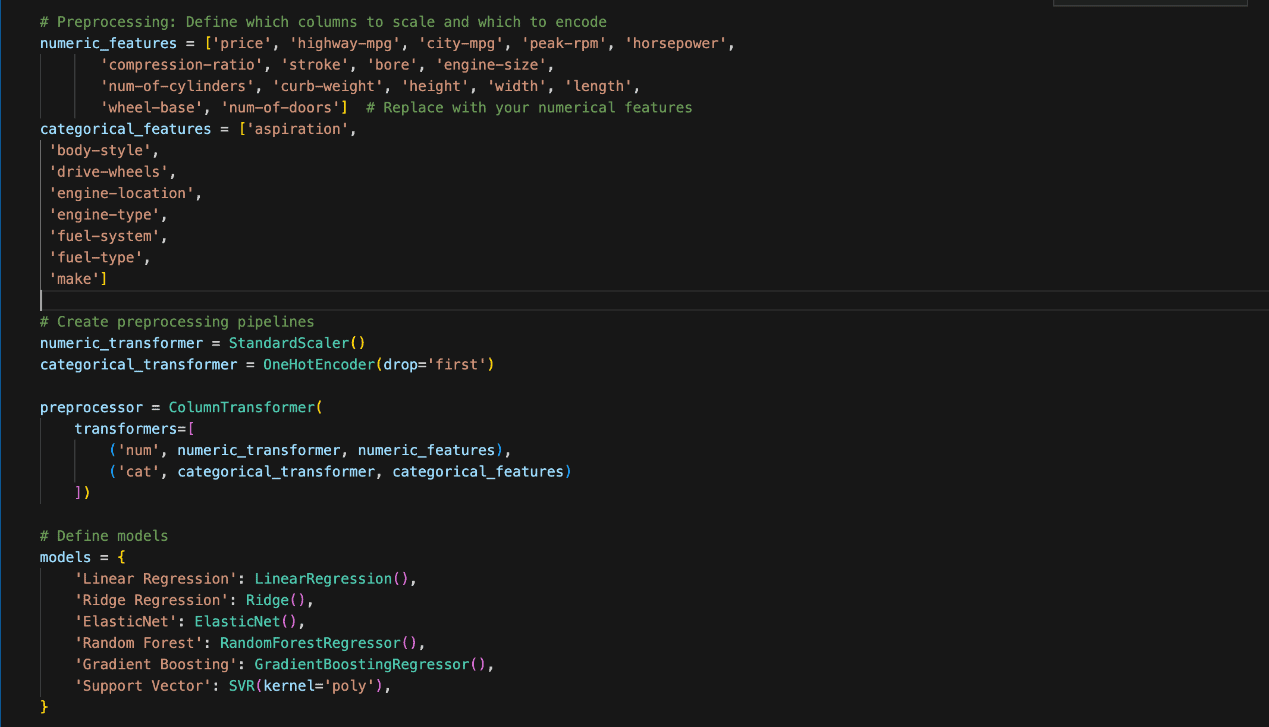
Preprocessing is important for getting ready the dataset earlier than making use of machine studying fashions. The Python coding within the determine beneath was used.
The options had been divided into two classes, particularly Numeric and Categorical.
The numeric options embrace values equivalent to ‘value’, ‘horsepower’, and ‘engine-size’. We scaled them utilizing StandardScaler to make sure all numeric variables have the identical weight when fed into the fashions.
Then again, the explicit or non-numeric options embrace ‘aspiration’, ‘body-style’, and ‘fuel-type’.
Categorical knowledge was reworked utilizing OneHotEncoder, which converts them into binary columns with 1 representing the presence and 0 representing the absence of every class.
Mannequin Choice
A number of algorithms will be utilised within the prediction of normalised losses within the vehicle insurance coverage enterprise.
Nevertheless, the efficiency of those algorithms will fluctuate relying on the character of the dataset and the particular downside to be tackled.
Subsequently, you will need to check out a number of algorithms and evaluate them based mostly on sure analysis standards to pick out the very best one whereas additionally aiming to stability complexity and interpretability.
Under are the algorithms thought of and explored.
1. Linear Regression
Linear Regression is without doubt one of the easiest machine studying fashions. It tries to discover a straight line (or hyperplane) that most closely fits the info.
The concept is that the goal variable ‘y’ (like ’normalised-loss’`) will be expressed as a linear mixture of the enter options ‘x’ (like’`value’,’`horsepower’, and so on.). Study extra about Linear Regression here.
The purpose of Linear Regression is to minimise the error between the expected and precise values. The error is measured utilizing the imply squared error (MSE).
2. Ridge Regression
Ridge Regression is like Linear Regression however with a penalty for big coefficients (weights). This helps stop overfitting.
Math is sort of the identical as Linear Regression, but it surely provides a regularisation time period that penalises massive weights.
Study extra about Ridge Regression here.
3. Random Forest Regressor
Random Forest is an ensemble methodology that mixes a number of Determination Timber. A choice tree splits the info into smaller teams, studying easy guidelines (like “if value > 10,000, predict excessive loss”).
A Random Forest builds many resolution timber and averages their outcomes. The randomness comes from:
– Deciding on a random subset of knowledge for every tree.
– Utilizing random subsets of options at every cut up.
Every tree makes its personal prediction, and the ultimate result’s the common of all tree predictions.
Necessary ideas:
– Splitting Standards: In regression, timber are often cut up by minimising the imply squared error (MSE).
– Bagging: This implies every tree is educated on a random subset of the info, which makes the forest extra sturdy.
Extra about Random Forest here.
4. Gradient Boosting Regressor
Gradient Boosting is one other ensemble methodology that builds resolution timber. Nevertheless, in contrast to Random Forest, every tree learns from the errors of the earlier one. It really works by becoming timber sequentially.
The primary tree makes predictions, and the following tree focuses on correcting the errors made by the earlier tree.
Study Gradient Boosting Regressor here.
5. Help Vector Regressor (SVR)
Support Vector Regressor tries to discover a line (or hyperplane) that most closely fits the info, however as an alternative of minimising the error for all factors, it permits a margin of error. SVR makes use of a boundary the place it doesn’t care about errors (a margin).
SVR tries to stability minimising errors and holding the mannequin easy by solely adjusting predictions outdoors this margin.
6. ElasticNet
ElasticNet combines the concepts of Lasso Regression and Ridge Regression. Like Ridge, it penalises massive coefficients but in addition like Lasso, it may well scale back some coefficients to zero, making it helpful for characteristic choice.
ElasticNet is sweet when you may have many options and need each regularisation and have choice.
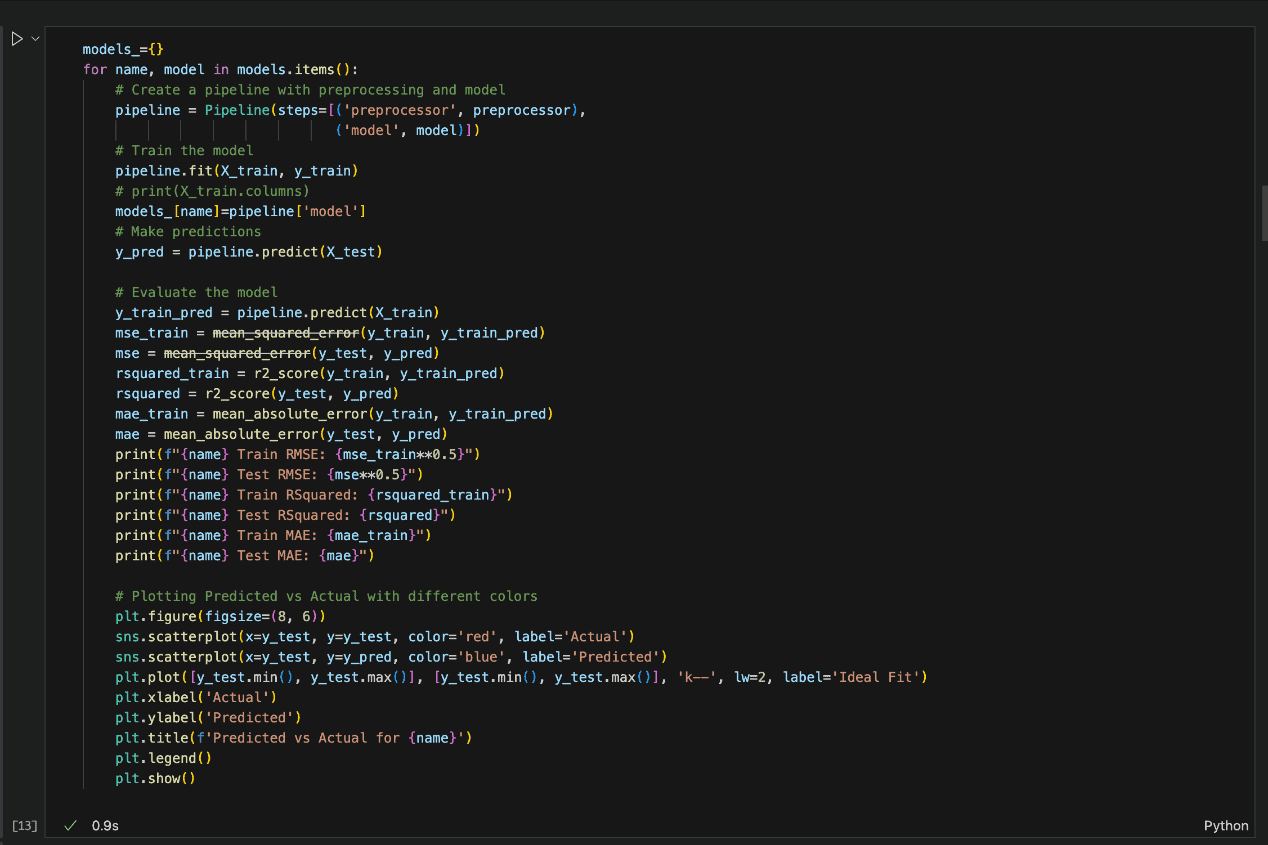
Mannequin Analysis
A number of the extra generally recognized mannequin analysis strategies or metrics used on this mission are RMSE, MSE, and R-squared.
Splitting the dataset into coaching and check units is an analysis methodology used earlier than the primary mannequin is even constructed.
By setting apart a portion of the info because the check set, we be certain that the mannequin is evaluated on unseen knowledge, offering an early and unbiased estimate of how effectively the mannequin will generalise new knowledge.
After experimenting with totally different algorithms utilizing the check cut up ratio, the next efficiency metrics had been used to check the regression fashions on an equal footing:
Imply Squared Error (MSE):
MSE measures the common squared distinction between the precise and predicted values.
A decrease MSE signifies a greater match, but it surely’s delicate to outliers.
Root Imply Squared Error (RMSE):
The RMSE is the sq. root of MSE, and it’s helpful as a result of it’s in the identical items because the goal variable.
Imply Absolute Error (MAE):
MAE measures the common absolute distinction between the precise and predicted values.
It’s much less delicate to outliers than MSE.
R-squared (R²):
R² explains how a lot of the variance within the goal variable is captured by the mannequin.
The next R² (nearer to 1) signifies a greater match, but it surely’s not all the time dependable for small datasets.
Within the snapshot of the Python code beneath, every of the mannequin algorithm and the analysis methodology is applied.
Outcomes
The next desk summarises the outcomes of the totally different fashions used based mostly on RMSE, MAE, and R-squared values:
|
Fashions |
RMSE |
MAE |
R-squared |
|
Linear Regression |
16.4 |
13.9 |
80.5 |
|
Ridge Regression |
23.4 |
17.7 |
60.3 |
|
Random Forest Regressor |
26.8 |
18.4 |
48.2 |
|
Gradient Boosting Regressor |
23.5 |
15.1 |
60.0 |
|
Help Vector Regressor |
36.7 |
33.9 |
2.8 |
|
Elastic Internet |
28.7 |
25.6 |
40.4 |
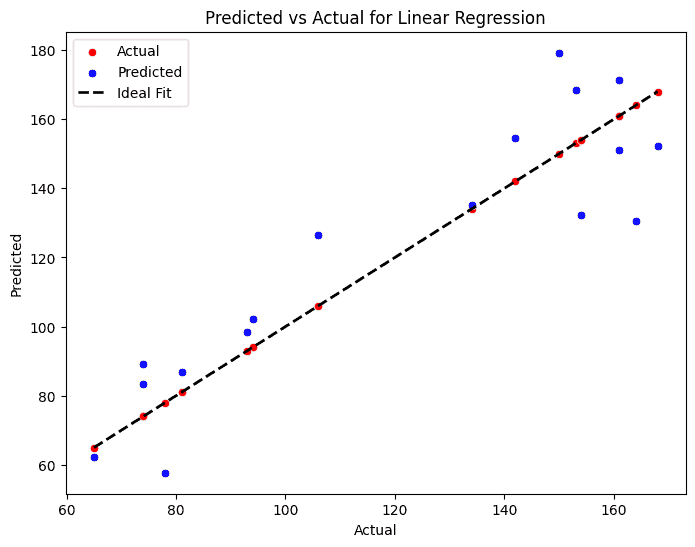
From the outcomes offered, Linear Regression appears to reveal the very best total efficiency in comparison with the opposite fashions, adopted by Gradient Boosting Regressor and Random Forest.
Nevertheless, it may very well be noticed that the tree-based fashions (Random Forest and Gradient Boosting Regressor) could also be exhibiting indicators of overfitting.
Whereas their coaching efficiency is close to excellent, their check efficiency is considerably worse, indicating that these fashions might not generalize effectively to unseen knowledge.
|
Fashions |
RMSE prepare |
RMSE check |
MAE prepare |
MAE check |
R-Squared prepare |
R-Squared check |
|
Random Forest Regressor |
6.9 |
26.8 |
4.3 |
18.4 |
96.1 |
48.2 |
|
Gradient Boosting Regressor |
4.1 |
23.5 |
3.1 |
15.1 |
98.6 |
60.0 |
Hyperparameter Tuning
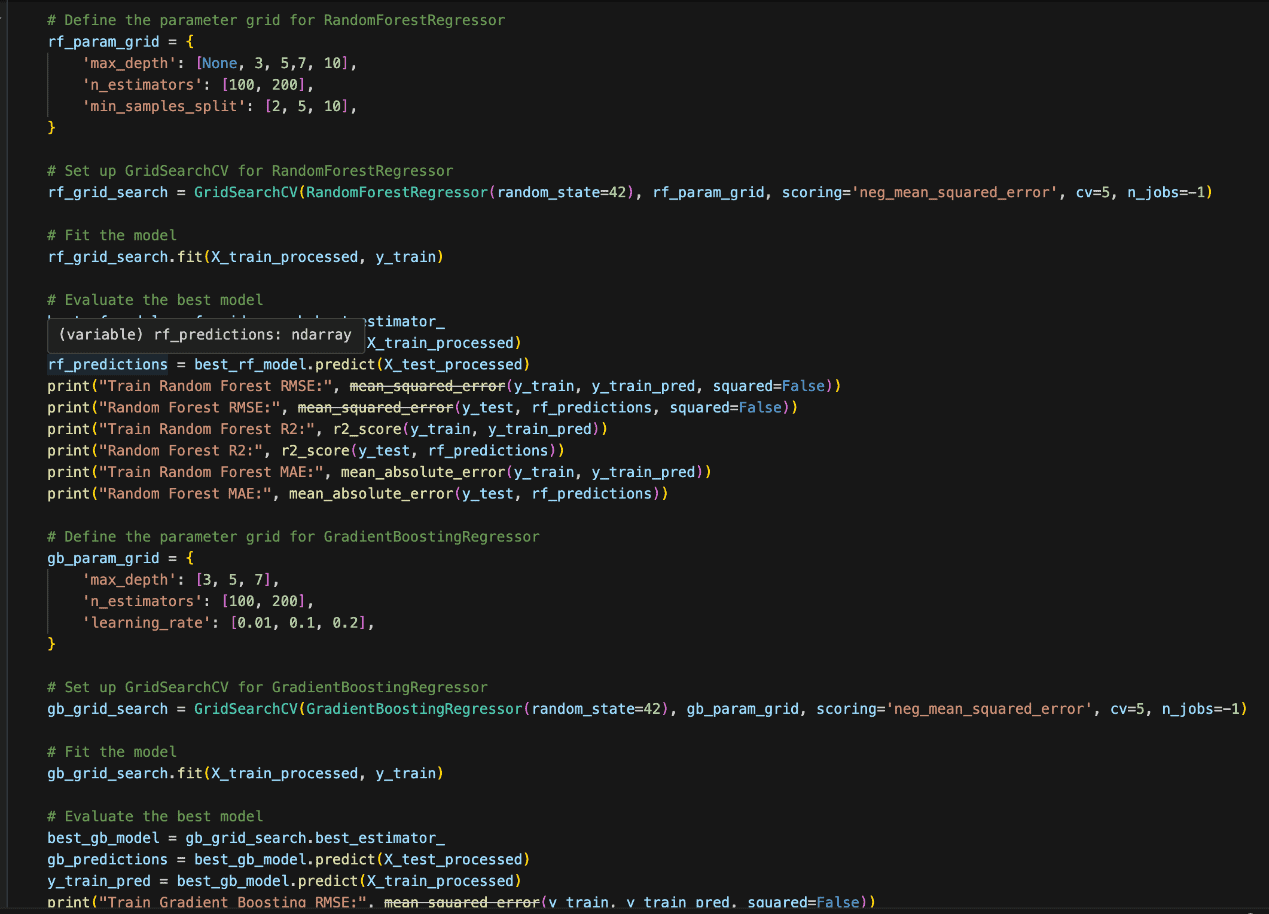
Selecting the best hyperparameters can considerably enhance the mannequin’s efficiency and its skill to generalise to unseen knowledge. If the hyperparameters should not tuned appropriately:
- The mannequin may overfit (carry out effectively on coaching knowledge however poorly on check knowledge).
- The mannequin may underfit (fail to seize the patterns within the knowledge).
The right way to Carry out Hyperparameter Tuning
- Guide Search: You manually attempt totally different combos of hyperparameters and consider efficiency. This strategy will be time-consuming and inefficient.
- Grid Search: You outline a set of hyperparameter values to attempt, and the algorithm tries each mixture. It’s exhaustive however computationally costly, particularly when the search area is massive.
Since we’ve a comparatively small pattern dimension, we will probably be utilizing grid search as seen within the Python code snippet beneath:
Outcomes after tuning
|
Fashions |
RMSE prepare |
RMSE check |
MAE prepare |
MAE check |
R-Squared prepare |
R-Squared check |
|
Random Forest Regressor |
8 |
25.2 |
5.7 |
19.3 |
94.8 |
54.1 |
|
Gradient Boosting Regressor |
5.1 |
21.9 |
3.8 |
15.2 |
97.9 |
65.8 |
Though the coaching scores for the tree-based fashions have decreased and the check scores have improved, the hole between the 2 nonetheless signifies indicators of overfitting.
This implies that, regardless of the changes, the fashions wrestle to generalise.
Total, Linear Regression stays the top-performing mannequin, exhibiting no indicators of overfitting and delivering sturdy, balanced outcomes throughout each coaching and check datasets.
Function Significance
To additional improve the interpretability of your mannequin, it’s important to grasp which options contribute essentially the most to the ultimate predictions.
The strategy for evaluating characteristic significance varies by mannequin kind. For tree-based fashions like Random Forest or Gradient Boosting, we might utilise the built-in characteristic significance methodology.
For Linear Regression, the mannequin’s coefficients will be analysed. Bigger absolute values point out options which have essentially the most important impression on the mannequin’s predictions.
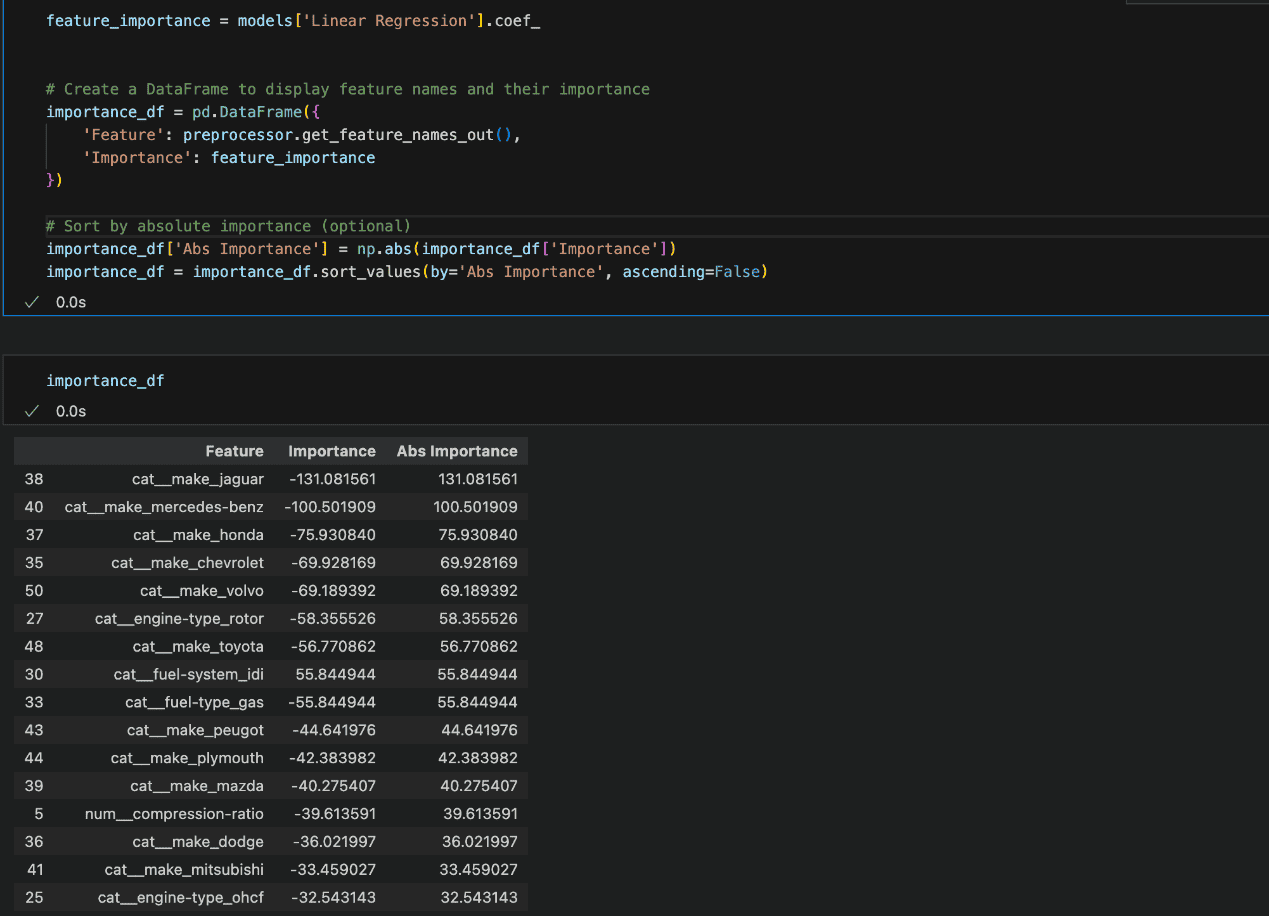
The characteristic significance reveals that the classes reworked into options by means of one-hot encoding have the biggest coefficients.
This implies that these categorical variables, as soon as cut up into binary columns, have a major affect on the mannequin’s predictions.
It’s widespread in such circumstances for sure classes inside a characteristic to hold extra weight, particularly in the event that they symbolize distinct patterns or behaviors that strongly impression the result.
Nevertheless, it’s essential to rigorously interpret these outcomes, as massive coefficients don’t essentially imply the characteristic is inherently essential—simply that it has a stronger relationship with the goal within the given mannequin.
Mannequin Interpretability utilizing SHAP
One other methodology of calculating characteristic significance is by utilizing SHAP.
SHAP (SHapley Additive exPlanations) is a strong characteristic significance software that makes use of cooperative sport principle to assign every characteristic an significance worth based mostly on its contribution to a mannequin’s predictions.
By computing Shapley values, SHAP quantifies how a lot every characteristic influences the output for particular person predictions, enabling a transparent understanding of mannequin conduct.
To calculate characteristic significance utilizing SHAP, this methodology will be adopted:

The SHAP plot displayed beneath reveals the significance of various options on the mannequin’s predictions. The SHAP values on the x-axis point out the extent to which every characteristic influences the mannequin’s output, with optimistic or destructive contributions.
The additional the SHAP worth is from zero, the stronger the characteristic’s impression on the prediction. The colours symbolize the characteristic values: blue for low values and pink for top values.
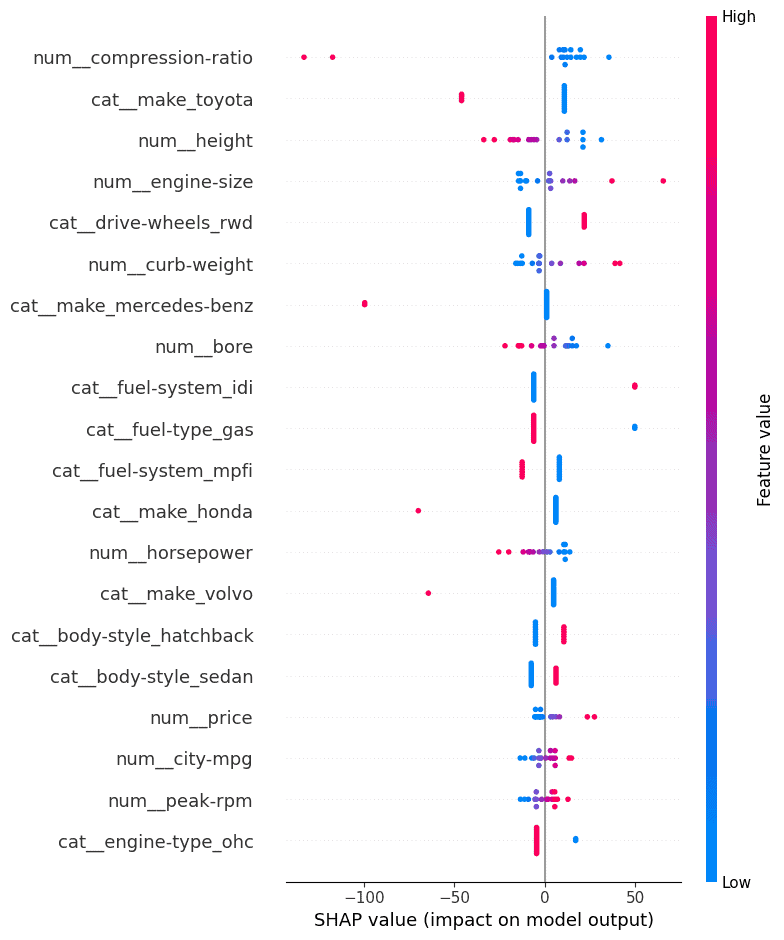
Key Observations:
- Compression-ratio (num__compression-ratio) has essentially the most important impression, with increased values (in pink) growing the SHAP values and positively influencing the mannequin’s predictions. Conversely, decrease compression ratios (in blue) push the prediction within the destructive route.
- Make Toyota (cat__make_toyota) additionally has a robust affect. Excessive SHAP values recommend that vehicles of this make contribute positively to the mannequin’s end result.
- Top (num__height) reveals a transparent pattern the place increased values contribute positively, and decrease values push predictions downward.
- Engine dimension (num__engine-size) and curb weight (num__curb-weight) are among the many high options, with bigger engines and heavier autos typically contributing to increased predictions. This aligns with expectations, as these attributes usually correlate with automobile efficiency.
- Make Mercedes-Benz (cat__make_mercedes-benz) have a definite impact, with increased SHAP values driving the prediction positively, reflecting its luxurious standing.
- The drive wheels (cat__drive-wheels_rwd) characteristic, notably rear-wheel drive vehicles, are inclined to affect predictions positively when rear-wheel drive is current.
- This SHAP evaluation reveals that among the most influential options are associated to automobile specs (engine dimension, curb weight, top) and particular automobile make (Toyota, Mercedes-Benz).
Enterprise implications of automobile insurance coverage threat prediction outcomes
- Insurance coverage Premium Calculation: By predicting normalized losses, insurance coverage corporations can extra precisely set premiums for various automobile fashions. Vehicles with increased predicted normalized losses can be thought of riskier, resulting in increased premiums, and vice versa.
- Threat Evaluation for New Automotive Fashions: Automotive producers or sellers might use this mannequin to evaluate the insurance coverage threat score of latest or upcoming automobile fashions. This helps in evaluating how dangerous it may be to insure the automobile based mostly on its options and the historical past of comparable autos.
- Accident/Declare Threat Prediction: Predicting normalised losses might point out how susceptible a automobile is to accidents or injury based mostly on options like engine dimension, horsepower, or physique kind, permitting producers or shoppers to evaluate the probability of incurring future restore prices.
- Car Score Programs: Predicting normalized losses can contribute to a extra complete automobile score system for patrons, serving to them make knowledgeable choices concerning the long-term prices of proudly owning a specific automobile, together with insurance coverage bills.
Wrapping up
In abstract, this mission demonstrates the facility of predictive modeling in estimating normalised losses for autos.
Among the many fashions examined, Linear Regression emerged as the highest performer, hanging an efficient stability between accuracy and ease.
Superior fashions like Random Forest and Gradient Boosting, whereas promising, exhibited challenges with overfitting, underscoring the significance of cautious mannequin tuning and analysis.
The evaluation additionally highlighted the vital options influencing predictions, equivalent to engine dimension, curb weight, and particular automobile make, offering actionable insights for stakeholders.
By leveraging these fashions, insurance coverage corporations can optimise premium pricing, producers can assess threat scores for brand spanking new fashions, and shoppers could make extra knowledgeable automobile buy choices.
This strategy exemplifies how machine studying can bridge the hole between complicated knowledge and sensible, real-world functions.
Trending Merchandise









