
The dataset for this evaluation might be downloaded from GitHub utilizing this link. The Python code for the evaluation might be downloaded here.
Overview of the monetary fraud dataset
The dataset consists of 14,446 rows and 15 columns, with the next construction:
- Date and Time Options:
- trans_date_trans_time: Timestamp of the transaction.
- Transaction and Location Options:
- service provider: The identify of the service provider the place the transaction occurred.
- class: The class of the transaction, comparable to grocery_net, shopping_net, and many others.
- amt: The sum of money spent within the transaction.
- metropolis and state: The situation the place the transaction came about.
- lat and lengthy: Latitude and longitude of the transaction location.
- merch_lat and merch_long: Latitude and longitude of the service provider’s location.
- Demographic and Private Options:
- city_pop: The inhabitants of town the place the transaction came about.
- job: The job title of the person making the transaction.
- dob: The date of start of the person, at the moment in object format.
- trans_num: A novel identifier for the transaction.
- Goal Variable:
- is_fraud: Signifies whether or not the transaction was fraudulent (1) or not (0).
Step-by-step evaluation plan
1. Knowledge Cleansing and Preprocessing:
- Convert trans_date_trans_time to datetime format.
- Convert dob to datetime format and calculate the age of the person on the time of the transaction.
- Convert is_fraud from an object to an integer for simpler evaluation.
2. Exploratory Knowledge Evaluation (EDA):
- Univariate Evaluation: Analyse the distribution of the important thing variables comparable to amt, city_pop, and age.
- Bivariate Evaluation: Discover the connection between amt and different options like class, city_pop, and is_fraud.
- Geospatial Evaluation: Plot the geographic distribution of transactions and determine any patterns associated to fraud.
3. Evaluation of Fraudulent Transactions utilizing Machine studying
Characteristic engineering:
- Create further options comparable to transaction_hour, transaction_day_of_week, and transaction_month from the trans_date_trans_time.
- Calculate the gap between the transaction location (lat, lengthy) and the service provider’s location (merch_lat, merch_long).
Predictive modelling:
- Examine the distribution of options in fraudulent vs. non-fraudulent transactions.
- Determine key indicators of fraud primarily based on the dataset.
4. Additional Evaluation
- Visualise the distribution of transaction quantities, the age distribution of shoppers, and the geographic distribution of fraud.
- Use field plots, histograms, and scatter plots to know relationships and outliers.
STEP 1. Knowledge Cleansing and Preprocessing:
The next Python script would clear and rework the information and make it prepared for evaluation by:
- Changing trans_date_trans_time to datetime format.
- Changing dob to datetime format and calculate the age of the person on the time of the transaction.
- Changing is_fraud from an object to an integer for simpler evaluation.
# Knowledge Cleansing and preprocessing
df['trans_date_trans_time'] = pd.to_datetime(df['trans_date_trans_time'], format="%d-%m-%Y %H:%M")
df['dob'] = pd.to_datetime(df['dob'], format="%d-%m-%Y")
df['age'] = df['trans_date_trans_time'].dt.12 months - df['dob'].dt.12 months
df['is_fraud'] = df['is_fraud'].str.extract('(d)').astype(int)STEP 2. EDA.
Univariate evaluation:
We’ll begin with a univariate evaluation to know the distribution of key options like amt, age, and city_pop.
The univariate evaluation reveals the next insights:
The distribution of transaction quantities is right-skewed, with most transactions being comparatively small. A number of transactions have considerably increased quantities, indicating potential outliers.
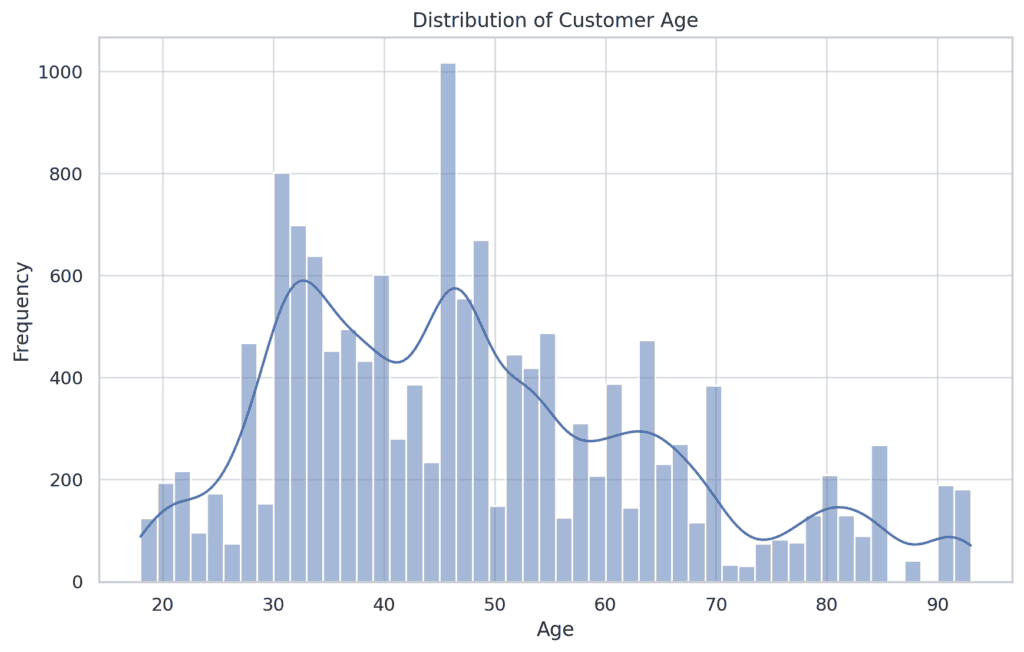
The age distribution exhibits a focus of shoppers within the center age vary, with fewer youthful and older clients. This distribution seems to be barely left-skewed.
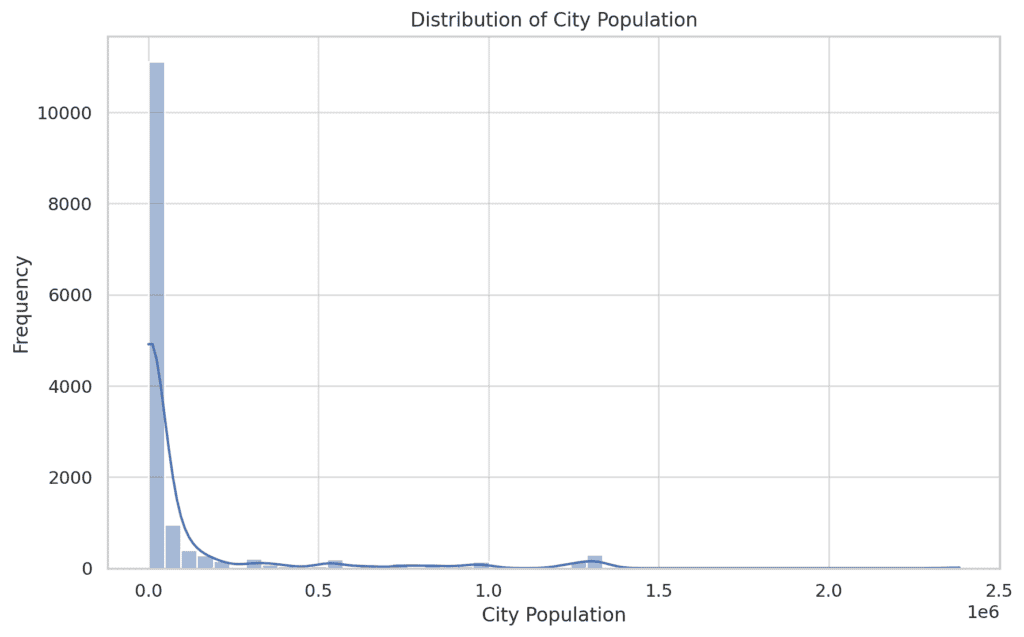
Town inhabitants distribution is closely right-skewed, indicating that almost all transactions happen in smaller cities, with a number of happening in bigger cities.
Bivariate Evaluation:
We’ll carry out a bivariate evaluation to discover the relationships between key variables and the goal variable (is_fraud).
This may embrace analyzing how the transaction quantity, buyer age, and metropolis inhabitants relate to fraudulent exercise.
The bivariate evaluation supplies the next insights:
- Transaction Quantity vs. Fraud:
Fraudulent transactions are likely to have increased quantities in comparison with non-fraudulent transactions. This implies that top transaction quantities might be a possible indicator of fraud.
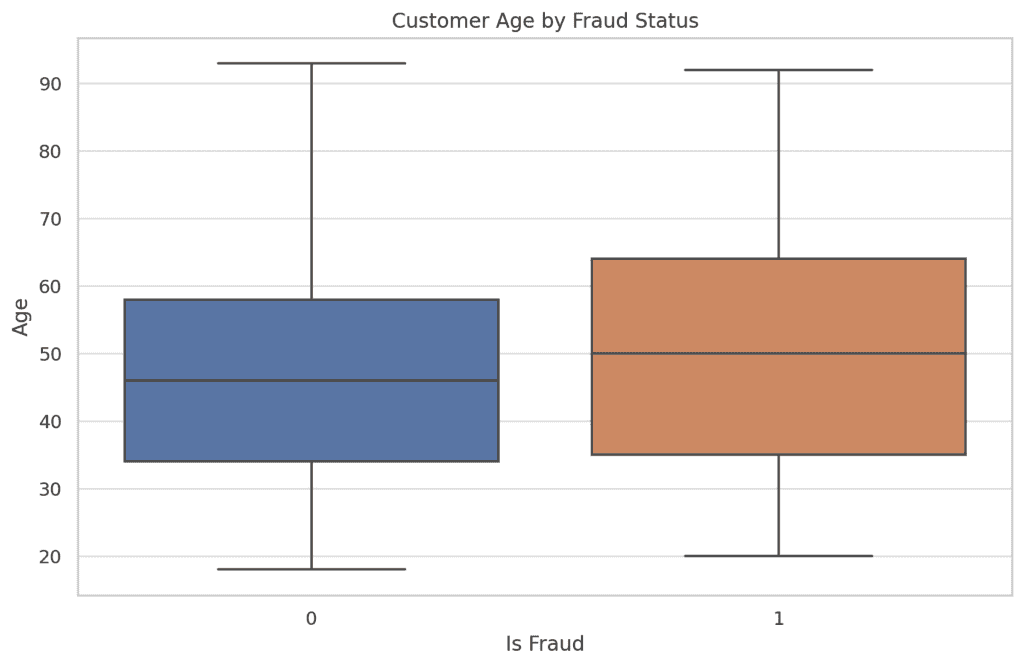
The age distribution for fraudulent transactions doesn’t considerably differ from non-fraudulent ones. This means that age may not be a robust predictor of fraud on this dataset.
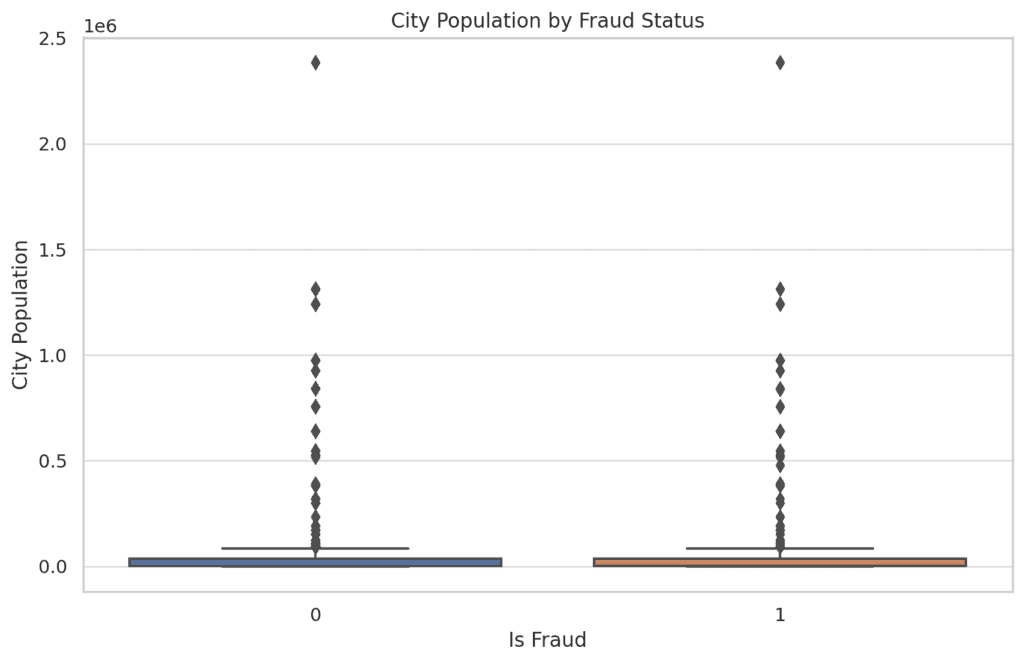
- Metropolis Inhabitants vs. Fraud:
Fraudulent transactions usually tend to happen in cities with smaller populations. This might suggest that fraudsters is likely to be concentrating on much less populated areas, presumably attributable to much less stringent safety measures.
Geospatial Evaluation:
We’ll conduct a geospatial evaluation to visualise the geographic distribution of transactions and determine any patterns associated to fraud.
The geospatial evaluation reveals the next:
- Geographic Distribution of Fraud:
Fraudulent transactions (marked in crimson) are unfold throughout varied areas, however there appears to be a focus in sure areas.
This implies that fraud exercise is likely to be extra prevalent in particular areas, which might be price additional investigation.
- Comparability with Non-Fraudulent Transactions:
Non-fraudulent transactions (marked in blue) are distributed extra evenly throughout the map. The overlap between fraudulent and non-fraudulent transactions signifies that fraud doesn’t solely happen in remoted areas however quite inside areas of standard transaction exercise.
STEP 3. Evaluation of Fraudulent Transactions utilizing machine studying.
Characteristic Engineering:
First, we’ll refine and create further options that would enhance the predictive energy of our mannequin. We’ll then construct and check a predictive mannequin to determine fraudulent transactions.
We’ll create the next further options that are related to the evaluation utilizing the next Python code:
- Transaction Frequency: The variety of transactions made by a person in a given timeframe (e.g., day by day, weekly).
- Service provider Consistency: The frequency of transactions on the identical service provider by the identical person.
- Distance Anomalies: The connection between the gap of the transaction from the person’s dwelling location and whether or not it was fraudulent.
- Transaction Hour: The hour when the transaction occurred.
- Transaction Day of Week: The day of the week when the transaction occurred.
- Transaction Month: The month when the transaction occurred.
# Characteristic Engineering
df['transaction_hour'] = df['trans_date_trans_time'].dt.hour
df['transaction_day_of_week'] = df['trans_date_trans_time'].dt.dayofweek
df['transaction_month'] = df['trans_date_trans_time'].dt.month
def calculate_distance(row):
trans_location = (row['lat'], row['long'])
merch_location = (row['merch_lat'], row['merch_long'])
return geodesic(trans_location, merch_location).kilometers
df['distance_to_merch'] = df.apply(calculate_distance, axis=1)
df['daily_transaction_count'] = df.groupby(df['trans_date_trans_time'].dt.date)['trans_num'].rework('depend')
df['merchant_consistency'] = df.groupby(['job', 'merchant'])['trans_num'].rework('depend')Predictive Modelling:
Subsequent, we’ll use these options, together with the unique ones, to construct a predictive mannequin.
We’ll use these Python script to do the next:
- Break up the information into coaching and testing units.
- Construct a mannequin (utilizing Random Forest Classifier) to foretell whether or not a transaction is fraudulent.
- Consider the mannequin utilizing applicable metrics like accuracy, precision, recall, and F1-score.
# Mannequin Constructing
options = [
'amt', 'age', 'city_pop', 'distance_to_merch',
'daily_transaction_count', 'merchant_consistency',
'transaction_hour', 'transaction_day_of_week', 'transaction_month'
]
X = df[features]
y = df['is_fraud']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
mannequin = RandomForestClassifier(n_estimators=100, random_state=42)
mannequin.match(X_train, y_train)
y_pred = mannequin.predict(X_test)
report = classification_report(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(report)
print(conf_matrix)The Random Forest mannequin has produced the next outcomes:
Precision:
- For non-fraudulent transactions (class 0): 100%
- For fraudulent transactions (class 1): 100%
Recall:
- For non-fraudulent transactions: 100%
- For fraudulent transactions: 99%
F1-Rating:
- For non-fraudulent transactions: 100%
- For fraudulent transactions: 99%
Confusion Matrix:

- True Positives (fraud detected appropriately): 561
- True Negatives (non-fraud detected appropriately): 3768
- False Positives (non-fraud detected as fraud): 1
- False Negatives (fraud not detected): 4
Report Interpretation:
- The mannequin performs exceptionally nicely, with almost good precision, recall, and F1-scores.
- There are only a few misclassifications, with just one non-fraudulent transactions incorrectly categorized as fraud and 4 fraudulent transactions missed.
STEP 4. Additional Evaluation:
Fraud by Class
Let’s look at the distribution of fraud throughout completely different transaction classes to determine which classes are extra weak to fraudulent exercise.
The plot above reveals that sure transaction classes, comparable to shopping_net, grocery_pos, and misc_pos, exhibit the next incidence of fraud in comparison with others.
This implies that these classes is likely to be extra enticing or weak to fraudulent actions.
Evaluation of Fraud by Time.
Analysing fraud by time can present insights into when fraudulent actions are probably to happen. We are able to discover fraud patterns by:
- Hour of the Day: Understanding at which occasions of day fraud is extra frequent.
- Day of the Week: Figuring out whether or not sure days have increased fraud occurrences.
- Month of the Yr: Taking a look at seasonal patterns in fraud actions.
The visualisations of fraud by time present the next insights:
- Fraud by Hour of the Day:
Fraudulent transactions are extra frequent throughout sure hours, notably late at evening and early within the morning.
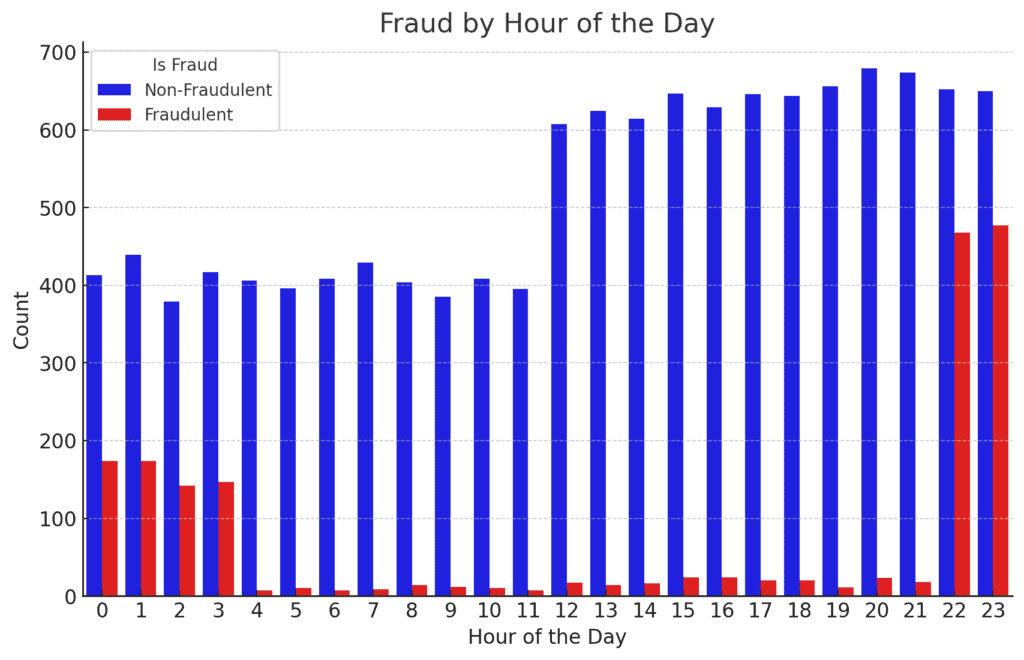
This would possibly point out that fraudsters desire to function once they anticipate decrease monitoring or fewer safety checks.
2. Fraud by Day of the Week:
Fraudulent transactions seem like pretty evenly distributed all through the week, with a slight enhance on weekends.
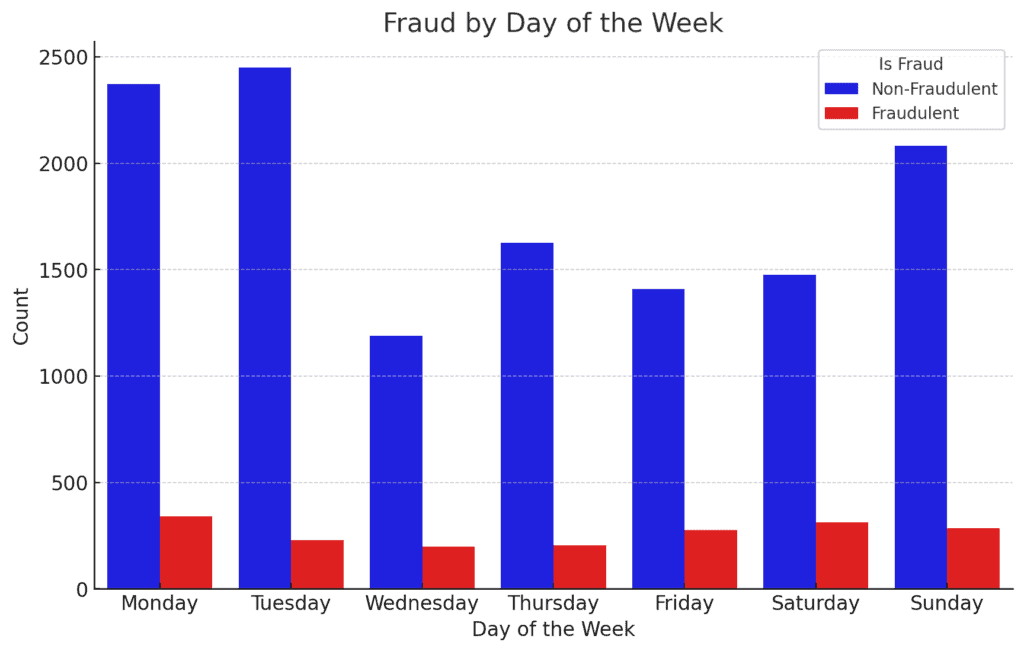
This might counsel that weekends is likely to be a extra opportunistic time for fraudsters, presumably attributable to diminished vigilance by monetary establishments.
3. Fraud by Month of the Yr:
The distribution of fraud throughout the months doesn’t present a really robust seasonal sample, although there are slight variations.
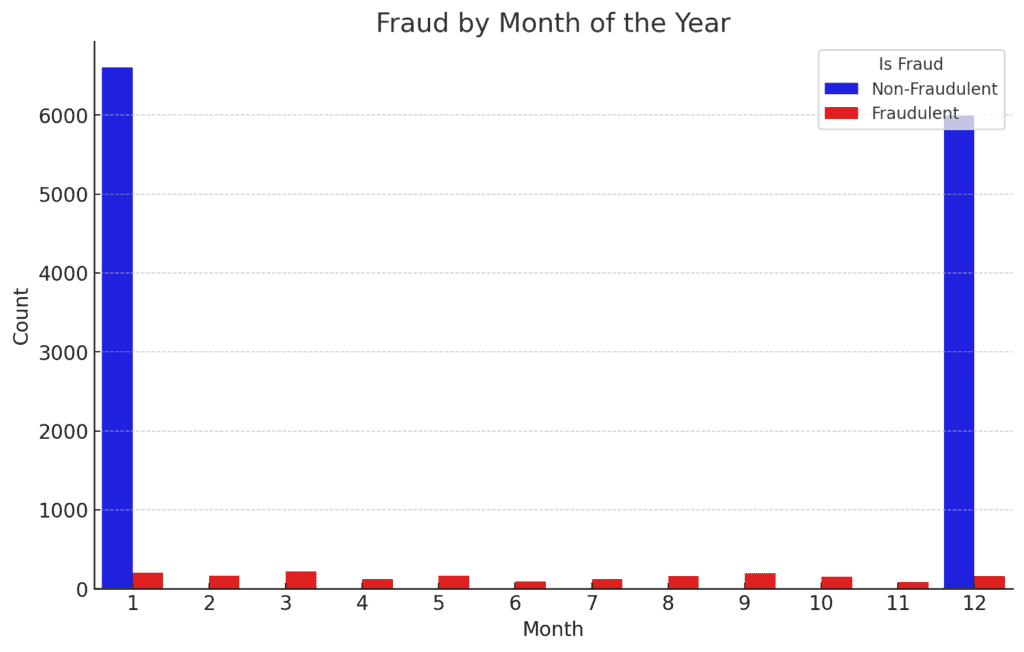
It is likely to be attention-grabbing to analyze additional if there are any particular occasions or holidays that correlate with these variations.
Conclusion
By way of this complete evaluation, we have now recognized a number of key patterns related to fraudulent transactions, together with increased transaction quantities, particular transaction classes, and sure geographic areas.
Our machine studying mannequin demonstrated robust efficiency in predicting fraud, and additional optimization might improve its accuracy much more.
By leveraging these insights, monetary establishments can implement extra focused fraud prevention measures, in the end decreasing the chance of fraud and defending each their property and their clients.
This evaluation serves as a basis for constructing extra subtle and adaptive fraud detection techniques sooner or later.
Trending Merchandise









