
The dataset for this evaluation might be downloaded from this GitHub link and here. The Python code for the evaluation might be downloaded here.
Notable Observations
Imbalance
The dataset appears imbalanced, with the next variety of ‘no’ responses in comparison with ‘sure’.
This is a crucial consideration when constructing predictive fashions, as it could have an effect on the efficiency and analysis metrics.
A number of methods (eg. SMOTE) can be utilized to handle this downside however could also be exterior the scope of our foremost goal for now.
Information High quality
Some options comprise ‘unknown’ classes, which can require preprocessing steps equivalent to imputation or exclusion. Utilizing these strategies would usually rely on the evaluation method.
Predictive Problem
The dataset poses a sensible and difficult downside for classification algorithms, making it appropriate for training and bench-marking numerous machine studying methods.
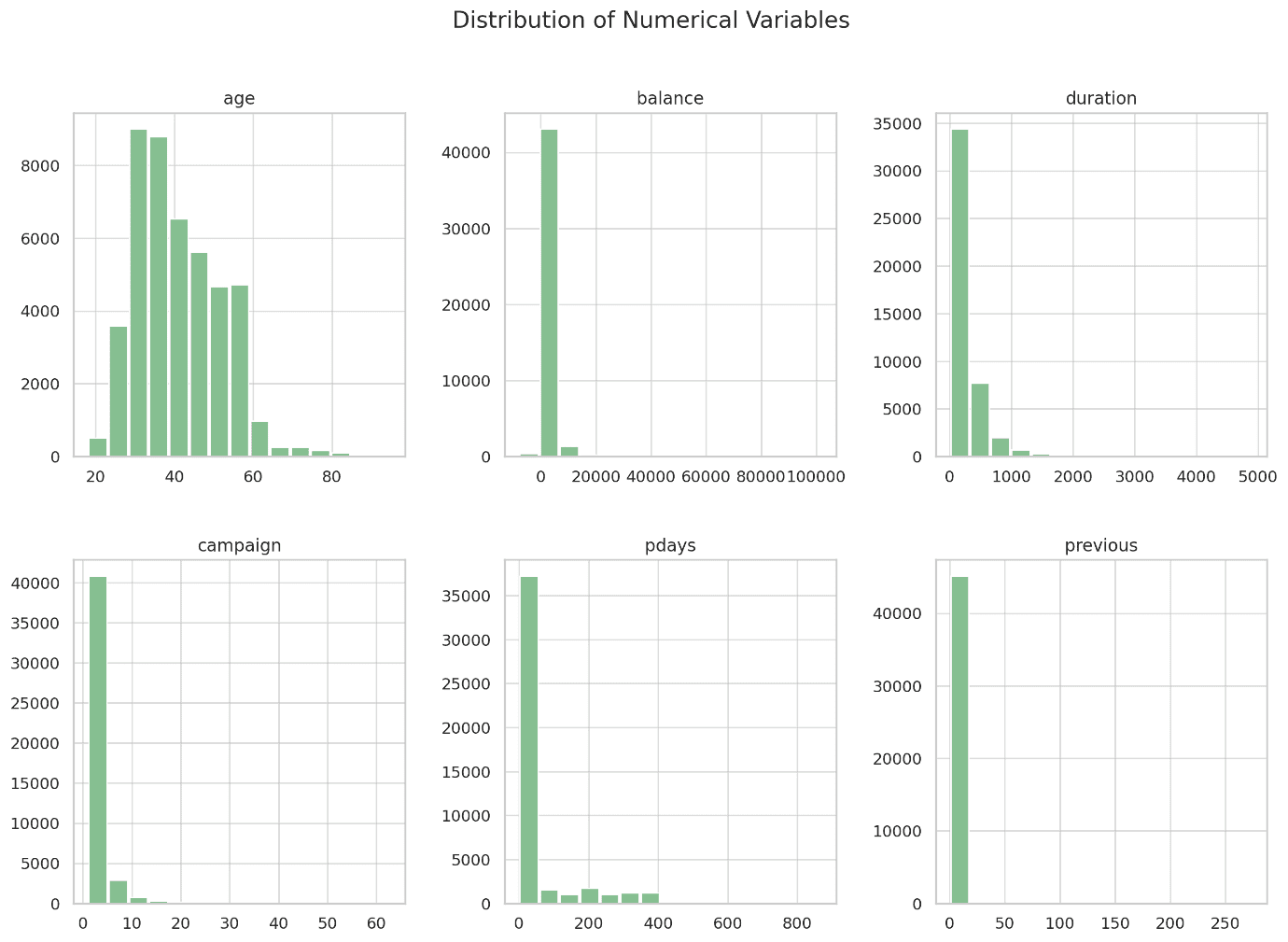
Abstract statistics
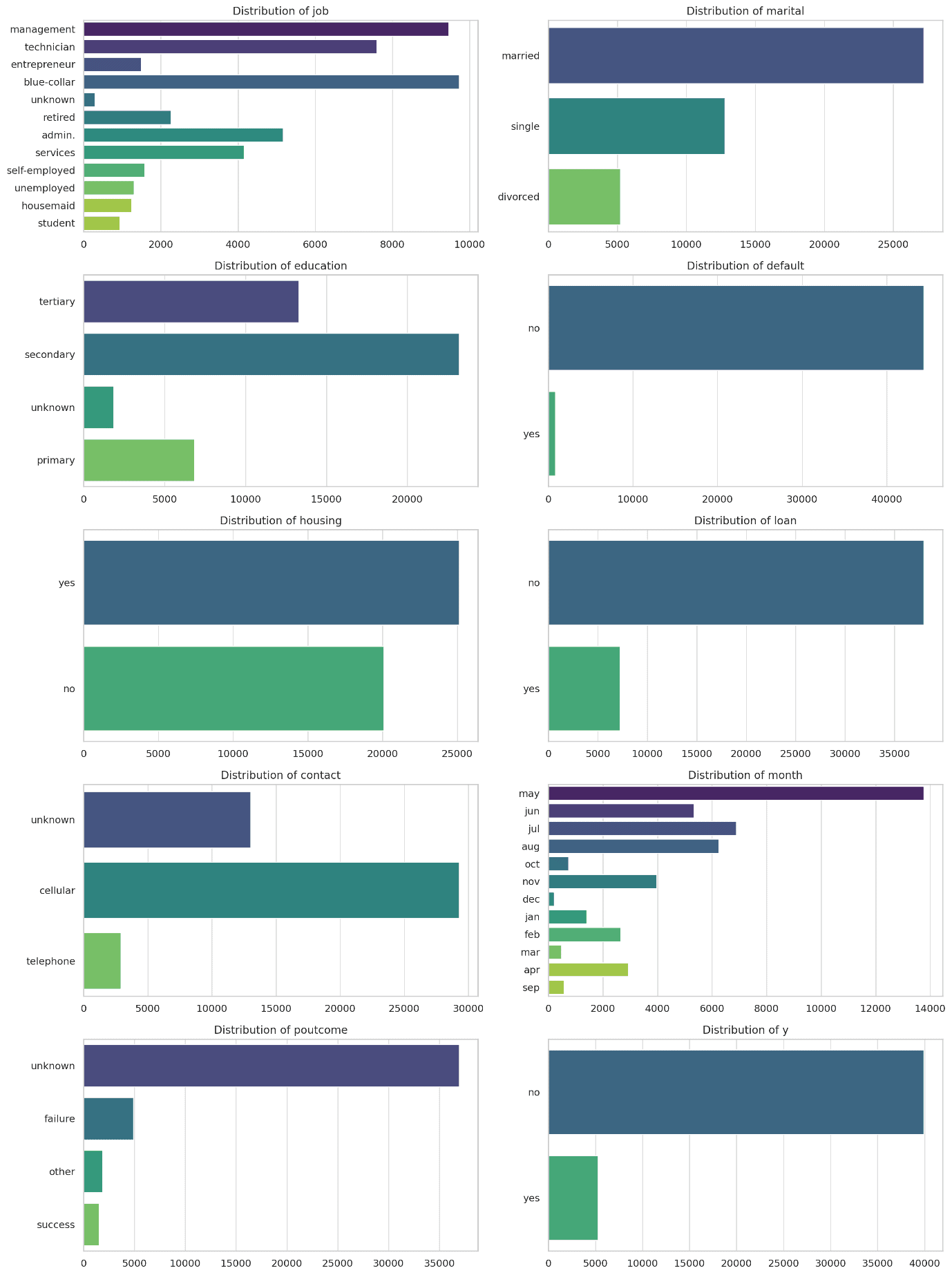
Categorical Variables
The abstract statistics for the numerical variables present a snapshot of the central tendencies and variability within the knowledge:
|
Measure |
Age |
Stability |
Day |
Period |
Marketing campaign |
Pdays |
Earlier |
|
Imply |
41 |
1362.27 |
16 |
258 |
3 |
40 |
1 |
|
Std |
11 |
3044.77 |
8 |
258 |
3 |
100 |
2 |
|
Min |
18 |
-8019.00 |
1 |
0 |
1 |
-1 |
0 |
|
Max |
95 |
102127.00 |
31 |
4918 |
63 |
871 |
275 |
- Age: The typical age is round 41 years, with a minimal of 18 and a most of 95.
- Stability: The typical account steadiness is 1362 items, however the giant commonplace deviation signifies vital variability. There’s additionally a notable damaging steadiness, with the minimal worth being -8019.
- Day: The “day” column represents the final contact day of the month, with values starting from 1 to 31.
- Period: Contact period varies broadly, with a mean of 258 seconds and a most of almost 5000 seconds.
- Marketing campaign: The variety of contacts carried out ranges from 1 to 63, with a mean of about 2.76.
- Pdays: This variable has a wide variety (from -1 to 871), indicating the times because the consumer was final contacted. The worth of -1 seems to be vital and sure signifies that the consumer had not been beforehand contacted.
- Earlier: The variety of contacts earlier than this marketing campaign, starting from 0 to 275.
Categorical Variables
- Job: The commonest job sorts are blue-collar, administration, and technician.
- Marital Standing: Most shoppers are married, adopted by single and divorced.
- Training: Secondary schooling is commonest, adopted by tertiary.
- Default: Virtually all shoppers shouldn’t have a credit score default.
- Housing: Numerous shoppers have housing loans.
- Mortgage: Most shoppers shouldn’t have a private mortgage.
- Contact: The vast majority of contacts are made utilizing unknown strategies, adopted by phone.
- Month: Might is the most typical month for contacts, adopted by August, July, and June.
- Poutcome: Most shoppers had no earlier final result recorded (unknown).
- Subscription (y): The goal variable exhibits {that a} minority of shoppers (round 11%) subscribed to a time period deposit.
Predictive Analytics
On this evaluation, a scientific method is adopted to construct and consider a predictive mannequin for figuring out whether or not a consumer will subscribe to a time period deposit.
The steps are outlined beneath:
Information Preprocessing
- Encoding Categorical Variables: Categorical variables are transformed into numeric format utilizing Label Encoding, making the information appropriate for machine studying algorithms.
- Characteristic Scaling: We standardised the numerical options to make sure that all options contribute equally to the mannequin’s predictions.
Dataset Splitting
- Coaching and Testing Cut up: The dataset was break up right into a coaching set (70%) and a testing set (30%) to coach the mannequin and consider its efficiency on unseen knowledge.
Mannequin Choice
- Random Forest Classifier: We selected a Random Forest classifier as a result of its robustness and skill to deal with complicated datasets with a number of options.
Mannequin Coaching
- The mannequin was educated utilizing the coaching knowledge to study the relationships between the options and the goal variable.
Mannequin Analysis
- Predictions: The mannequin made predictions on the take a look at set.
- Confusion Matrix: A confusion matrix was generated to guage the accuracy and error sorts (True Positives, False Positives, True Negatives, False Negatives).
- Classification Report: Precision, recall, and F1-score had been calculated to evaluate the mannequin’s efficiency.
- ROC Curve: The Receiver Working Attribute (ROC) curve and Space Underneath the Curve (AUC) had been plotted to guage the mannequin’s capacity to differentiate between the 2 courses (sure/no).
Predictive Analytics Outcomes
The Random Forest Classifier was used to foretell whether or not a consumer will subscribe to a time period deposit primarily based on the out there options.
Listed here are the outcomes:
Confusion Matrix
This matrix signifies that the mannequin is sort of efficient at predicting shoppers who is not going to subscribe, however much less so for many who will.
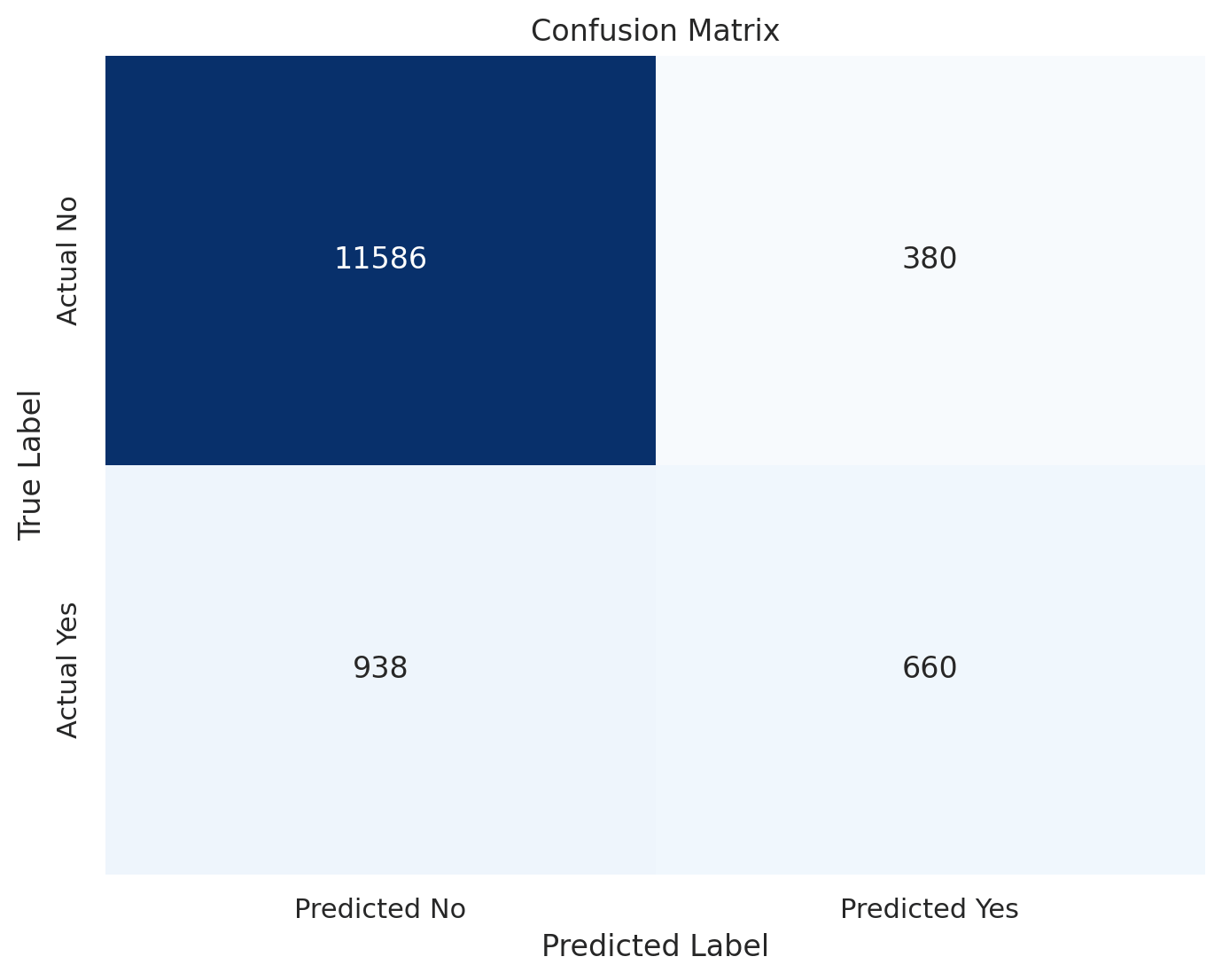
True Negatives (TN): 11,586
These are the cases the place the mannequin accurately predicted that the consumer would not subscribe to a time period deposit. It is a right rejection.
False Positives (FP): 380
These are the cases the place the mannequin predicted that the consumer would subscribe to a time period deposit, however the consumer truly didn’t.
It is a kind of error known as a “false alarm.”
False Negatives (FN): 938
These are the cases the place the mannequin predicted that the consumer would not subscribe to a time period deposit, however the consumer truly did.
It is a kind of error known as a “miss.”
True Positives (TP): 660
These are the cases the place the mannequin accurately predicted that the consumer would subscribe to a time period deposit.
It is a right identification.
Classification Report
General accuracy is 90%, with the mannequin performing a lot better at figuring out shoppers who is not going to subscribe (No) in comparison with those that will (Sure).
|
|
Precision |
Recall |
f1-score |
Assist |
|
No |
0.93 |
0.97 |
0.95 |
11966.00 |
|
Sure |
0.63 |
0.41 |
0.50 |
1598.00 |
|
Accuracy |
0.90 |
0.90 |
0.90 |
0.90 |
|
Macro Avg |
0.78 |
0.69 |
0.72 |
13564.00 |
|
Weighted Avg |
0.89 |
0.90 |
0.89 |
13564.00 |
Precision signifies how lots of the predicted “Sure” labels had been truly right. Right here, about 63% of the shoppers predicted to subscribe truly did so.
Recall exhibits how lots of the precise “Sure” instances had been accurately recognized by the mannequin. The mannequin accurately recognized about 41% of the shoppers who subscribed.
The F1-score for the optimistic class (“Sure”) is 0.50, indicating a average steadiness between precision and recall.
ROC-AUC Rating
The ROC-AUC rating of 0.924 signifies that the mannequin has an excellent capacity to differentiate between the 2 courses (Sure and No).
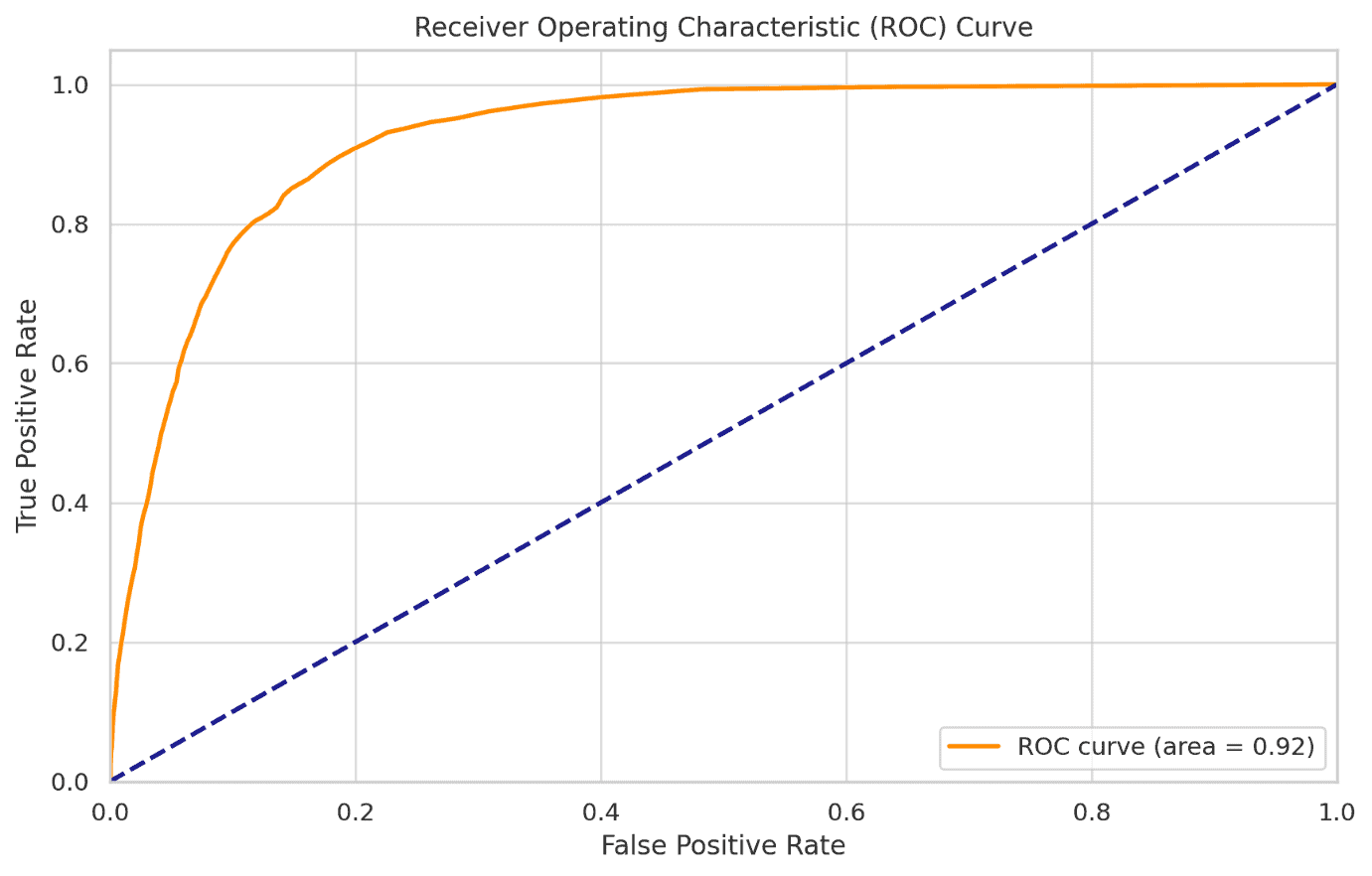
The ROC curve signifies an excellent steadiness between sensitivity (True Constructive Fee) and specificity (False Constructive Fee).
The world beneath the curve (AUC) of 0.924 additional confirms that the mannequin is efficient in distinguishing between shoppers who will and won’t subscribe to a time period deposit.
Abstract
Key findings from the evaluation embody:
- The mannequin achieved an general accuracy of 90%, with a powerful capacity to accurately determine shoppers who wouldn’t subscribe.
- The mannequin’s ROC-AUC rating of 0.924 signifies a excessive stage of discrimination between those that will and won’t subscribe.
- Nevertheless, the mannequin had a decrease recall for predicting optimistic instances (shoppers who subscribe), with a recall of 41% and a precision of 63%, indicating room for enchancment in figuring out potential subscribers.
Suggestions
Enhance Mannequin Sensitivity
- SMOTE (Artificial Minority Over-sampling Method) might need to be thought-about to steadiness the dataset or cost-sensitive studying to scale back the influence of false negatives. This can assist in higher figuring out potential subscribers.
- Experiment with different algorithms like Gradient Boosting Machines (GBM), XGBoost, or Neural Networks, which can provide higher efficiency for this classification job.
Characteristic Engineering
New options or interactions might need to be created between options that may enhance mannequin efficiency.
For instance, contemplate the consumer’s conduct over time or the mix of steadiness with different monetary indicators.
Conclusion
The prediction achieved a stable accuracy of 90%, indicating that it’s efficient in figuring out shoppers who’re unlikely to subscribe.
Nevertheless, the mannequin’s precision and recall for shoppers who do subscribe counsel that there’s room for enchancment, notably in decreasing the variety of false negatives.
By refining the mannequin and exploring various algorithms or extra options, banks can additional improve their predictive capabilities, resulting in extra focused and environment friendly advertising and marketing campaigns.
Finally, this data-driven method can assist monetary establishments not solely enhance their conversion charges but additionally foster stronger buyer relationships by means of personalised advertising and marketing efforts.
REFERENCES
Moro,S., Rita,P., and Cortez,P.. (2012). Financial institution Advertising and marketing. UCI Machine Studying Repository. https://doi.org/10.24432/C5K306.
Trending Merchandise









