The dataset for this evaluation may be downloaded from this GitHub link and here. The Python code for the evaluation may be downloaded here.
It incorporates eight columns that seize a mixture of demographic, life-style, and medical data as follows:
- Gender: The affected person’s gender (Male or Feminine).
- Age: The affected person’s age in years.
- Blood Stress (mmHg): The affected person’s blood stress measured in millimetres of mercury.
- Ldl cholesterol (mg/dL): The affected person’s ldl cholesterol stage measured in milligrams per decilitre.
- Has Diabetes: Signifies whether or not the affected person has been recognized with diabetes (Sure or No).
- Smoking Standing: The affected person’s smoking standing (By no means, Former, or Present).
- Chest Ache Kind: The kind of chest ache skilled by the affected person (Typical Angina, Atypical Angina, Non-anginal Ache, or Asymptomatic).
- Therapy: The therapy obtained by the affected person, which could possibly be Way of life Modifications, Angioplasty, Coronary Artery Bypass Graft (CABG), or Medicine.
This dataset affords a complete take a look at key elements that may affect the therapy method for coronary heart assault sufferers, offering a strong basis for predictive evaluation and insights into coronary heart illness administration.
Preliminary exploration
Abstract Statistics for Numerical Variables
|
Characteristic |
Imply |
Std Dev |
Min |
Max |
|
Age (Years) |
60.34 |
17.31 |
30 |
89 |
|
Blood Stress (mmHg) |
145.44 |
31.75 |
90 |
199 |
|
|
223.79 |
42.78 |
150 |
299 |
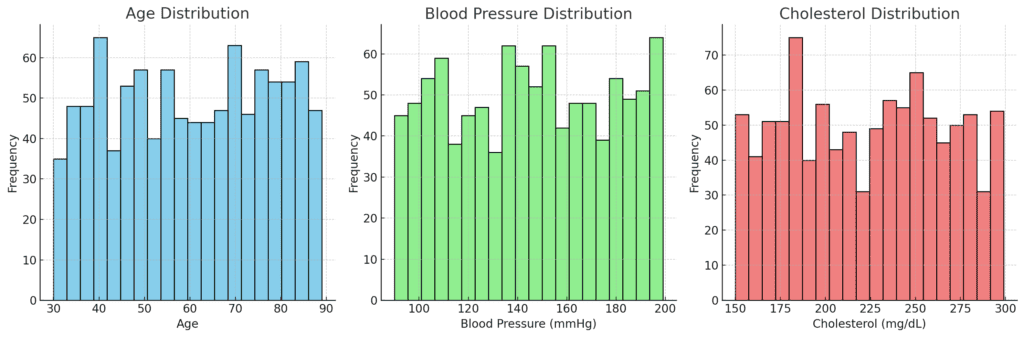
The sufferers are usually older, with a central age round 60 years. The large age vary suggests a various inhabitants when it comes to age, which is necessary since age is a big threat issue for coronary heart illness.
The common blood stress is barely above the traditional vary, indicating that many sufferers could have hypertension, which is a standard threat issue for coronary heart assaults.
Levels of cholesterol are comparatively excessive on common, which is predicted in a inhabitants with coronary heart illness.
Excessive ldl cholesterol is one other well-known threat issue for coronary heart assaults.
Distribution of Categorical Variables
|
Class |
Worth |
Depend |
|
Gender |
Feminine |
510 |
|
Gender |
Male |
490 |
|
Has Diabetes |
Sure |
517 |
|
Has Diabetes |
No |
483 |
|
Smoking Standing |
By no means |
352 |
|
Smoking Standing |
Present |
325 |
|
Smoking Standing |
Former |
323 |
|
Chest Ache Kind |
Non-anginal Ache |
261 |
|
Chest Ache Kind |
Asymptomatic |
255 |
|
Chest Ache Kind |
Typical Angina |
243 |
|
Chest Ache Kind |
Atypical Angina |
241 |
|
Therapy |
Way of life Modifications |
269 |
|
Therapy |
Coronary Artery Bypass Graft (CABG) |
252 |
|
Therapy |
Angioplasty |
247 |
|
Therapy |
Medicine |
232 |
- The information appears to counsel a virtually equal distribution of female and male sufferers. This tends to permit for gender-based comparisons in therapy and outcomes.
- Barely greater than half of the sufferers have diabetes, indicating a big overlap between diabetes and coronary heart illness on this inhabitants.
- The smoking standing is pretty evenly distributed, with a slight majority by no means having smoked. Nonetheless, the presence of present and former people who smoke highlights smoking as a notable threat issue on this group.
- The chest ache varieties point out a wide range of medical shows amongst coronary heart assault sufferers. This does counsel that chest ache sort could also be an necessary variable in understanding and predicting therapy outcomes.
- The even distribution of therapy appears to point a balanced method to therapy choices. This might make for an appropriate modelling and predictive evaluation with out bias towards a specific therapy sort.
Additional evaluation
Correlation Evaluation
Let’s establish the relationships between numerical variables utilizing the matrix beneath:
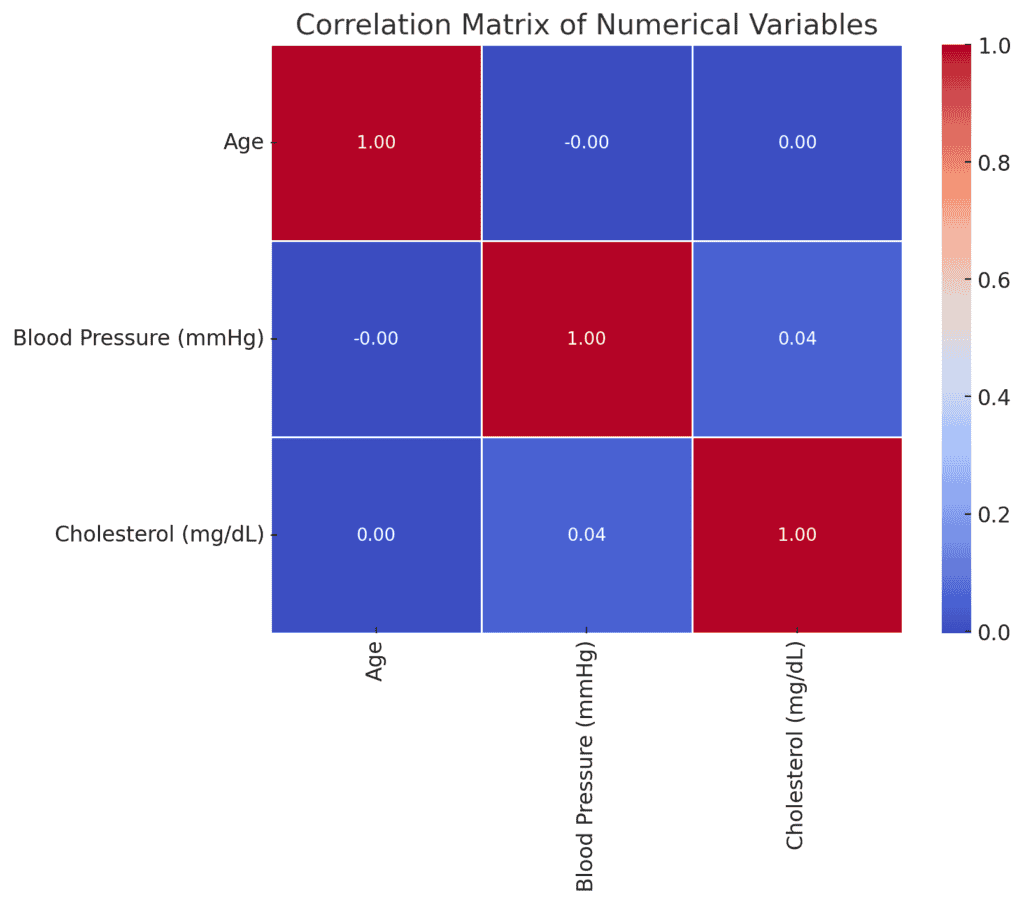
The correlation matrix reveals the next relationships among the many numerical variables:
Age
No important correlation with both blood stress or ldl cholesterol.
Blood Stress (mmHg)
A really weak optimistic correlation with ldl cholesterol (0.044).
Ldl cholesterol (mg/dL)
Basically no correlation with age or blood stress.
Typically, the weak correlations point out that, inside the dataset, age, blood stress, and levels of cholesterol are largely unbiased of each other.
This implies that these variables might not be robust predictors of one another on this context.
Given the low correlations among the many numerical variables, it could be extra insightful to discover relationships between categorical variables and outcomes, equivalent to therapies.
We are going to proceed with a Chi-Sq. Check for independence amongst categorical variables, notably specializing in relationships like:
- Smoking Standing and Therapy
- Has Diabetes and Therapy
- Gender and Therapy
This can assist decide if any important associations exist between these variables.
Chi-Sq. Check
Chi-Sq. assessments had been carried out to look at the relationships between categorical variables and therapy varieties. Under are the outcomes:
| Check | Chi2 | p-value | Levels of Freedom |
| Smoking Standing vs Therapy | 1.7973 | 0.9373 | 6 |
| Has Diabetes vs Therapy | 0.8026 | 0.8488 | 3 |
| Gender vs Therapy | 0.8967 | 0.8262 | 3 |
As could possibly be noticed, not one of the categorical variables (Smoking Standing, Has Diabetes, Gender) appear to point out a statistically important relationship with the therapy sort.
This implies that within the dataset, therapy choices are possible primarily based on elements apart from these demographic and life-style variables, or that these elements are equally distributed throughout completely different therapies.
Now let’s think about a predictive modelling utilizing machine studying to find out the therapy that may be administered given the variables within the dataset.
Predictive Modelling Strategy
Now we are going to proceed with a easy predictive modelling method by adopting the next process.
Particulars of the Python coding used are supplied within the hyperlink supplied at the start of this challenge.
Knowledge Preparation
- Encode categorical variables into numerical values since machine studying fashions usually require numerical enter.
- Cut up the dataset into options (X) and the goal variable (y) which, on this case, would be the Therapy column.
- Cut up the information into coaching and testing units to guage the mannequin’s efficiency.
Mannequin Choice
- We are going to use the Random Forest classifier, which is taken into account strong and offers characteristic significance that may assist in deciphering the mannequin.
Mannequin Coaching and Analysis
- Prepare the mannequin on the coaching set and consider its efficiency on the take a look at set.
- Metrics for use: Accuracy, Precision, Recall, F1-Rating, and presumably the ROC-AUC rating and confusion matrix.
Characteristic Significance
- Analyse which options are most necessary in predicting the therapy sort.
Predictive Modelling Outcomes
The Random Forest mannequin was educated and evaluated on the take a look at set. Listed below are the important thing outcomes:
|
Therapy Kind |
Precision |
Recall |
F1-Rating |
Help |
|
Angioplasty |
0.24 |
0.25 |
0.24 |
69 |
|
Coronary Artery Bypass Graft (CABG) |
0.28 |
0.32 |
0.3 |
75 |
|
Way of life Modifications |
0.25 |
0.29 |
0.27 |
78 |
|
Medicine |
0.35 |
0.23 |
0.28 |
78 |
|
macro avg |
0.28 |
0.27 |
0.27 |
300 |
|
weighted avg |
0.28 |
0.27 |
0.27 |
300 |
Classification Report
- Accuracy, Precision, Recall, and F1-Scores:
- The accuracy is 27.33% whereas the precision, recall, and F1-scores are round 0.24 to 0.35 for all therapy classes, indicating that the mannequin’s predictions are usually not extremely dependable.
- Help:
- The variety of situations for every therapy within the take a look at set is pretty balanced.
- ROC-AUC Rating: 0.524
- The ROC-AUC rating is barely higher than random guessing (which might be 0.5), however nonetheless signifies weak predictive energy.
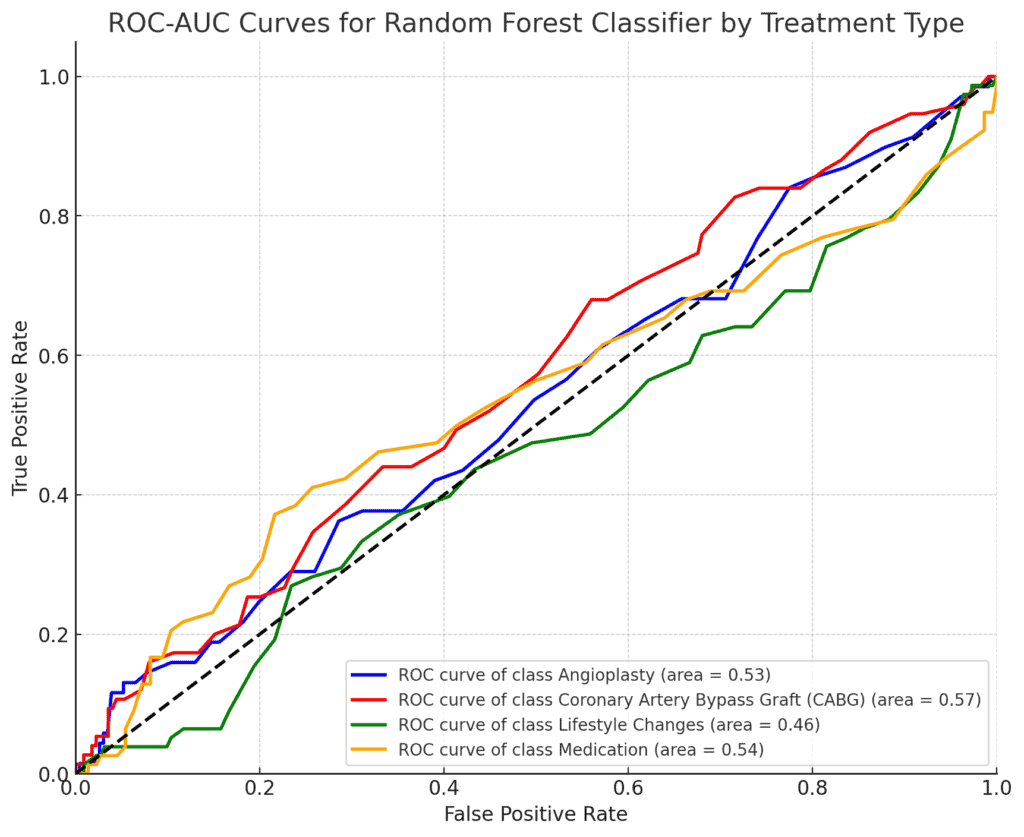
The low accuracy and ROC-AUC rating point out that the Random Forest mannequin isn’t successfully capturing the patterns wanted to foretell the therapy sort.
This may counsel that the options supplied are usually not robust predictors for therapy choices, or that extra complicated interactions between variables have to be thought-about.
Confusion Matrix
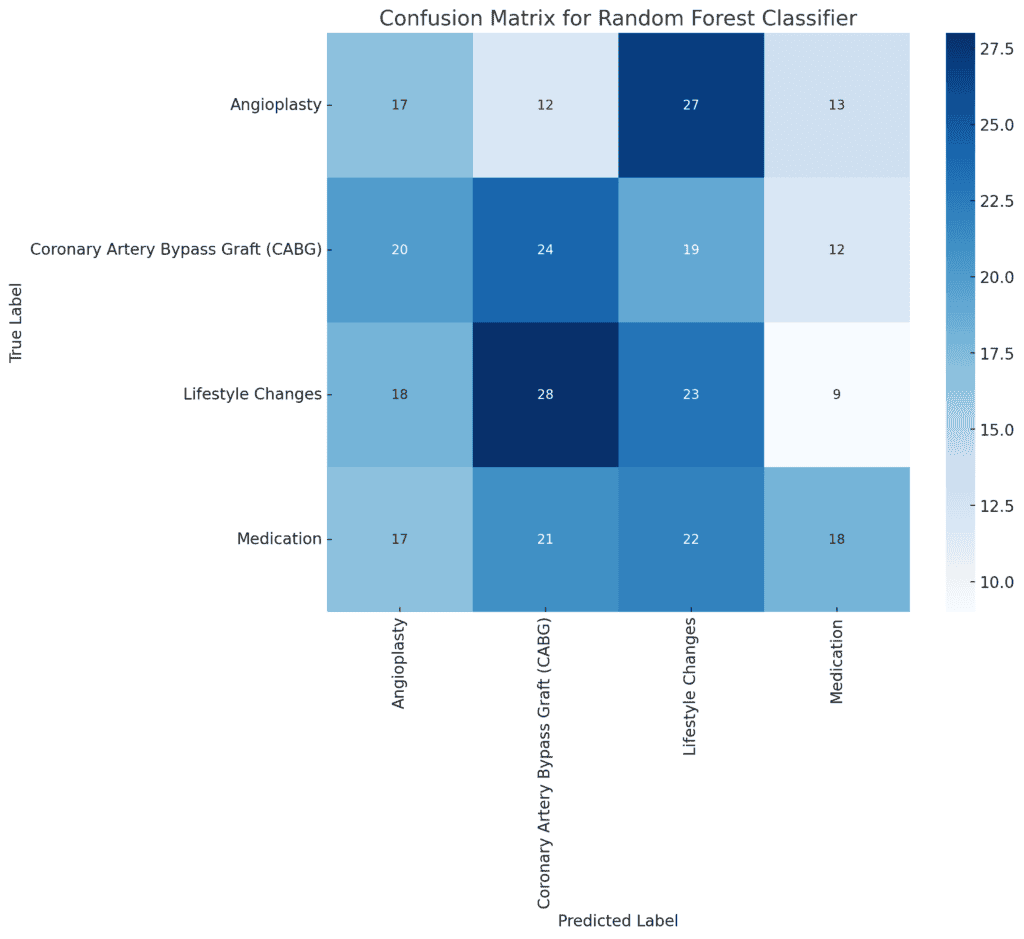
- True Positives (Diagonal Values):
These characterize instances the place the mannequin accurately predicted the therapy sort (e.g., 17 true positives for “Angioplasty”).
- False Positives (Off-Diagonal Values in Columns):
These happen when the mannequin incorrectly predicts a therapy sort that’s not the precise therapy (e.g., 14 instances had been incorrectly predicted as “Angioplasty” after they had been one other sort).
- False Negatives (Off-Diagonal Values in Rows):
These happen when the mannequin fails to foretell the precise therapy sort, as a substitute predicting one thing else (e.g., 16 instances of “Angioplasty” had been incorrectly predicted as different therapies).
Key Observations
- The confusion matrix reveals that the mannequin has some issue distinguishing between therapy varieties, as indicated by the variety of off-diagonal values.
- There isn’t any single class that the mannequin predicts very nicely, indicating that enhancements could possibly be made both by refining the mannequin or adjusting the options.
Evaluation of Characteristic Significance
Regardless that the mannequin’s efficiency isn’t robust, evaluation of characteristic significance may present insights into which variables, if any, have a bigger affect on the prediction.
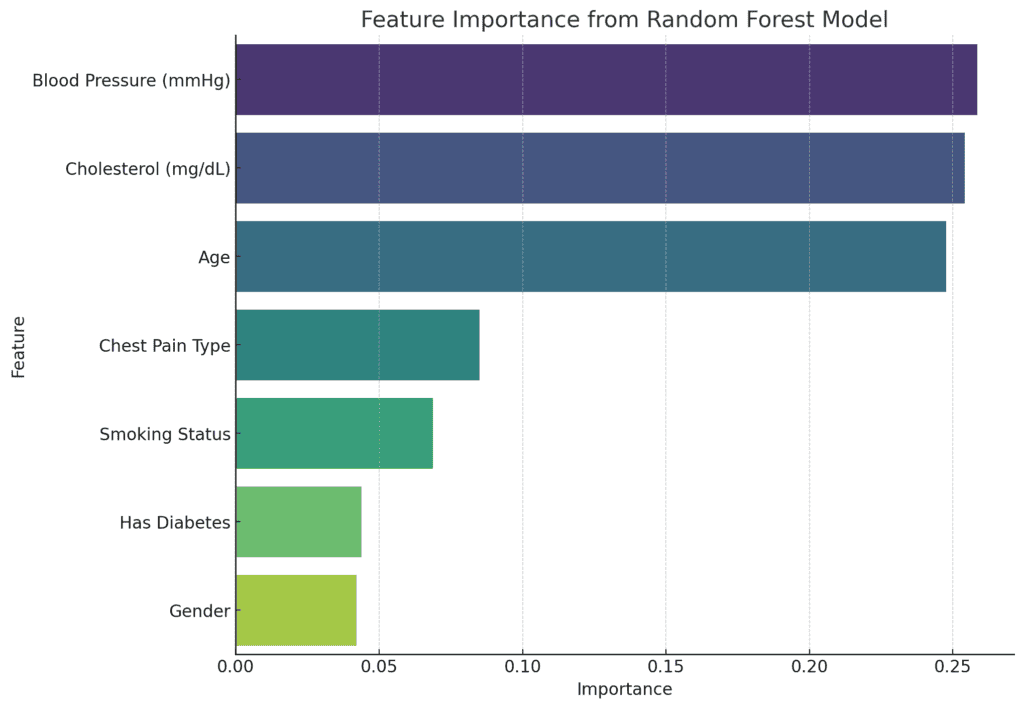
The characteristic significance extracted from the Random Forest mannequin reveals the relative contribution of every characteristic in predicting the therapy sort:
Prime Options:
- Blood Stress (mmHg): 25.84%
- Ldl cholesterol (mg/dL): 25.42%
- Age: 24.76%
These three numerical variables are essentially the most important in predicting the therapy sort, collectively accounting for about 75% of the mannequin’s decision-making course of.
Much less Essential Options:
- Chest Ache Kind: 8.51%
- Smoking Standing: 6.87%
- Has Diabetes: 4.38%
- Gender: 4.21%
The explicit variables appear to have a comparatively minor affect on the mannequin’s predictions, according to the sooner Chi-Sq. take a look at outcomes.
Nonetheless, the dominance of numerical options like blood stress, ldl cholesterol, and age means that these well being metrics play a bigger function in figuring out the therapy sort in comparison with life-style elements like smoking standing or the presence of diabetes.
Abstract and suggestions
Given that is solely a beginner-level challenge, additional evaluation could possibly be carried out to enhance the efficiency of a predictive modelling most particularly.
The next ideas could possibly be adopted for future evaluation:
Increase the Dataset
- Incorporate Extra Options: To enhance the mannequin’s predictive energy, think about including extra variables equivalent to household historical past of coronary heart illness, train habits, dietary data, stress ranges, and drugs adherence. These elements can present a extra holistic view of the affected person’s well being and contribute to raised predictions.
- Improve Pattern Dimension: A bigger dataset with extra affected person information may improve the mannequin’s capacity to generalise and enhance the robustness of the evaluation.
Mannequin Refinement
- Discover Superior Fashions: Whereas the Random Forest mannequin supplied some insights, exploring extra superior fashions equivalent to Gradient Boosting Machines (GBM), XGBoost, or deep studying fashions may yield higher efficiency.
- Hyperparameter Tuning: Optimise the efficiency of the Random Forest mannequin via hyperparameter tuning utilizing methods like grid search or randomised search to establish one of the best mixture of parameters.
Characteristic Engineering
- Create Interplay Phrases: Discover potential interactions between variables (e.g., the interplay between age and levels of cholesterol) to seize extra complicated relationships that may affect therapy choices.
- Categorical Characteristic Encoding: Experiment with completely different encoding methods, equivalent to one-hot encoding or goal encoding, to raised deal with categorical variables and enhance mannequin interpretability.
Mannequin Interpretability
- Utilise SHAP Values: Implement SHAP (SHapley Additive exPlanations) values to supply extra detailed insights into how particular person options contribute to the mannequin’s predictions, serving to to clarify why sure therapy choices are made.
- Choice Tree Visualisation: Take into account visualising particular person resolution timber inside the Random Forest to raised perceive the decision-making course of for various affected person profiles.
Conclusion
Our exploration of the guts assault dataset utilizing the Random Forest classifier reveals that whereas conventional well being metrics like blood stress, ldl cholesterol, and age play a big function in figuring out therapy outcomes, the predictive energy of the mannequin stays modest.
The evaluation highlights the complexity of therapy choices, suggesting that elements past the obtainable information could affect these choices.
Though the mannequin’s efficiency was restricted, the characteristic significance evaluation offers priceless insights into which variables are most influential.
This evaluation underscores the necessity for extra complete information and superior modelling methods to enhance predictions and in the end improve affected person care.
Trending Merchandise









